
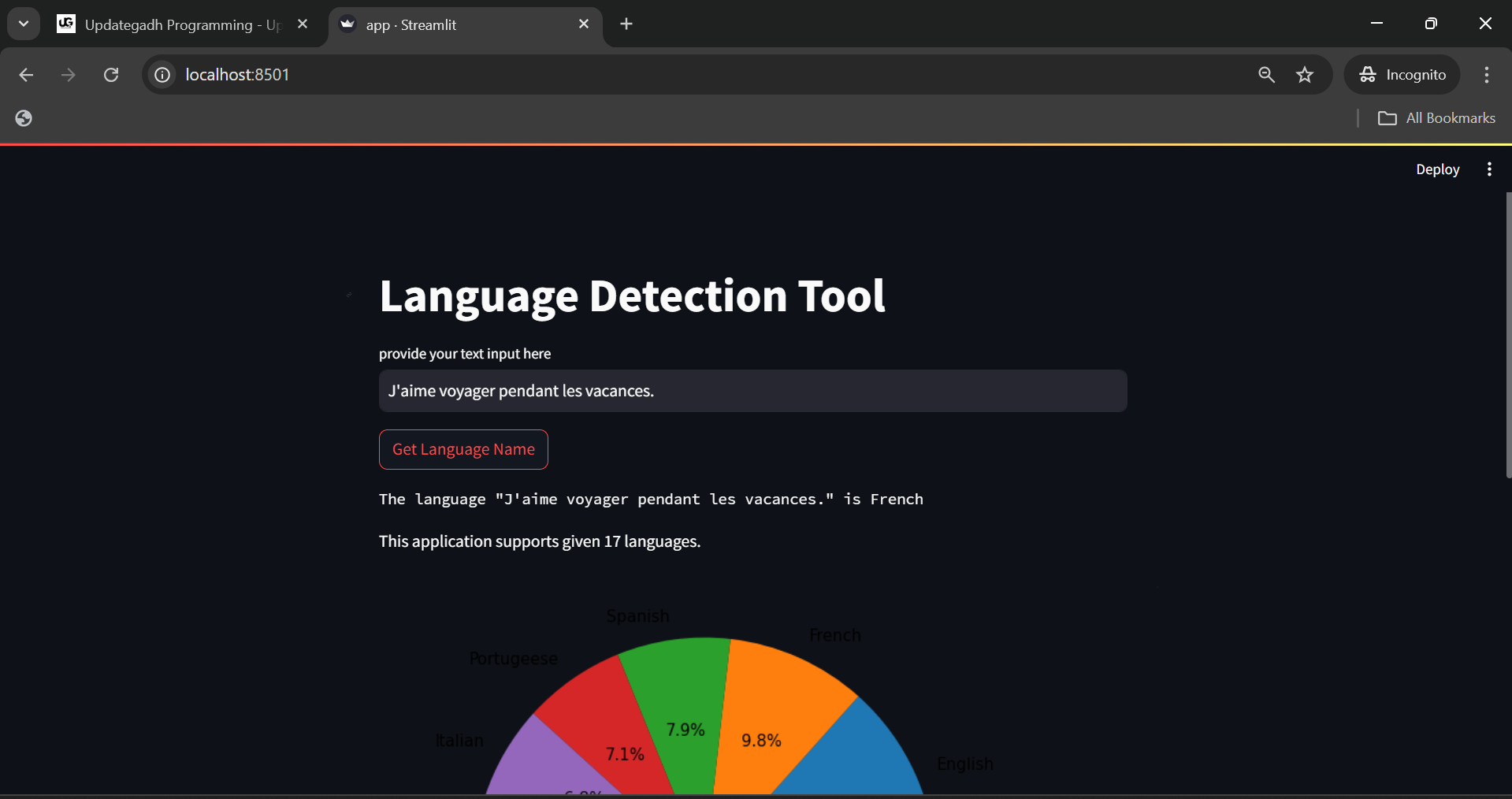
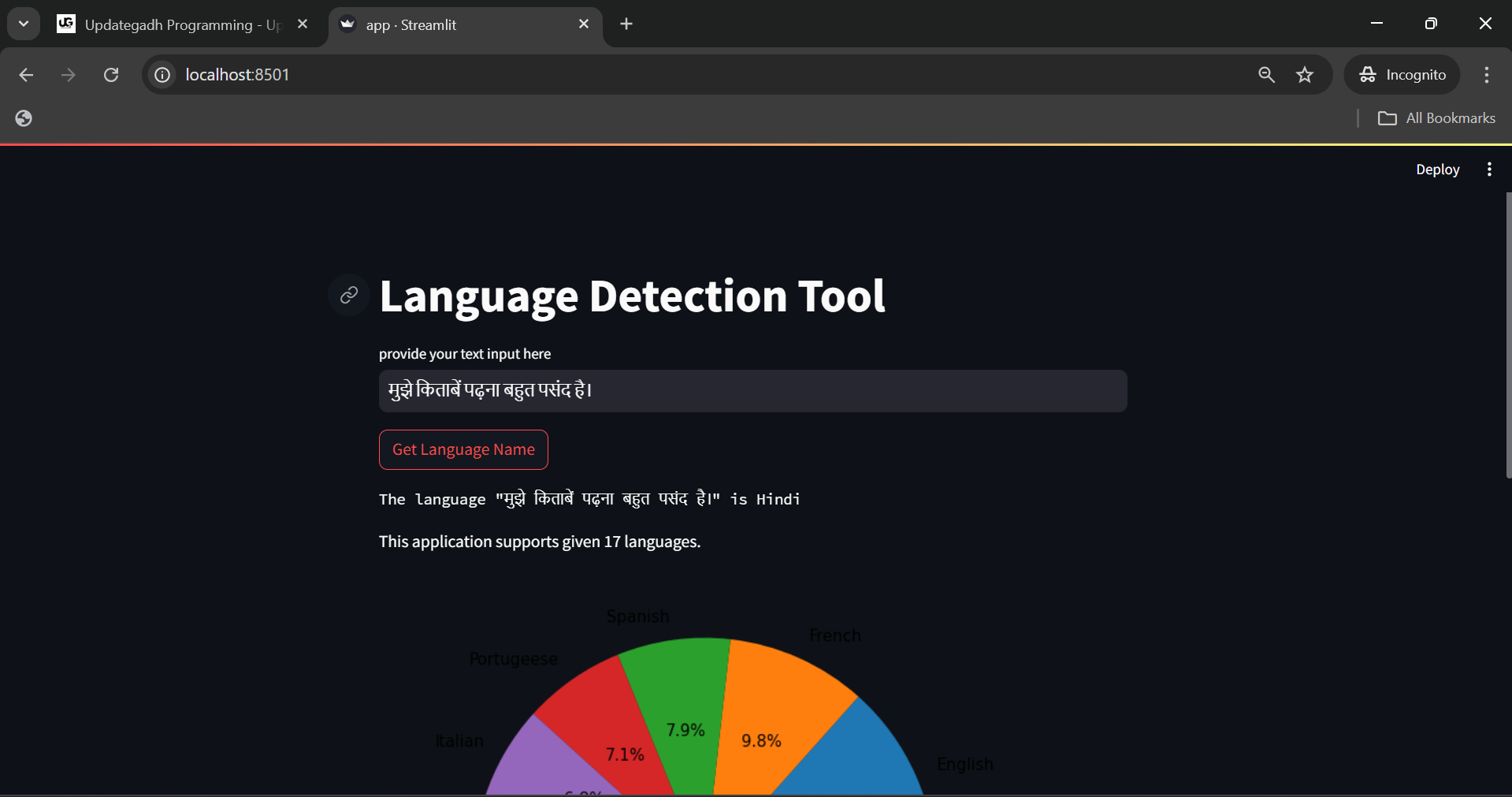
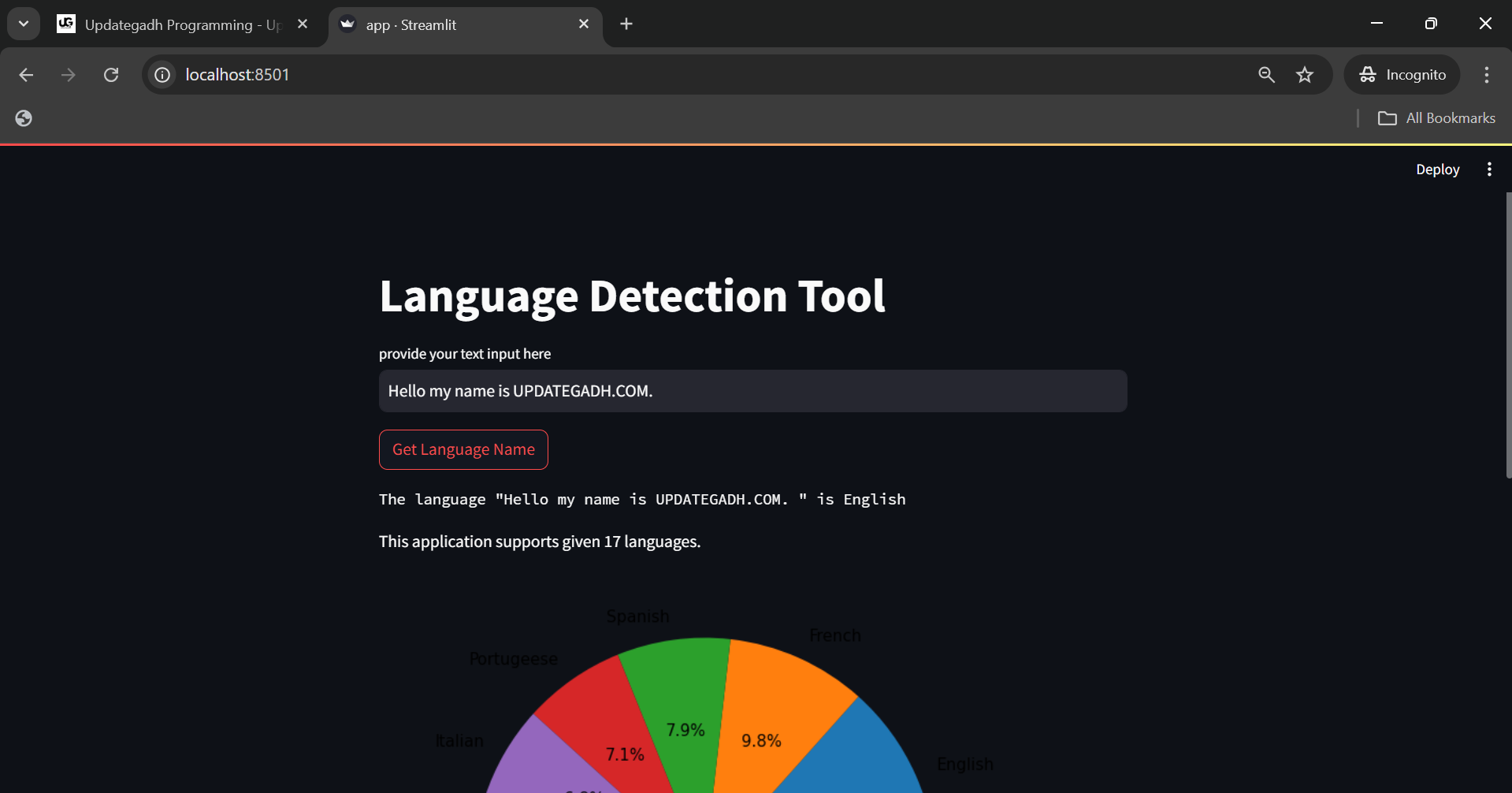
Best Language Detection Web App using Machine Learning & NLP
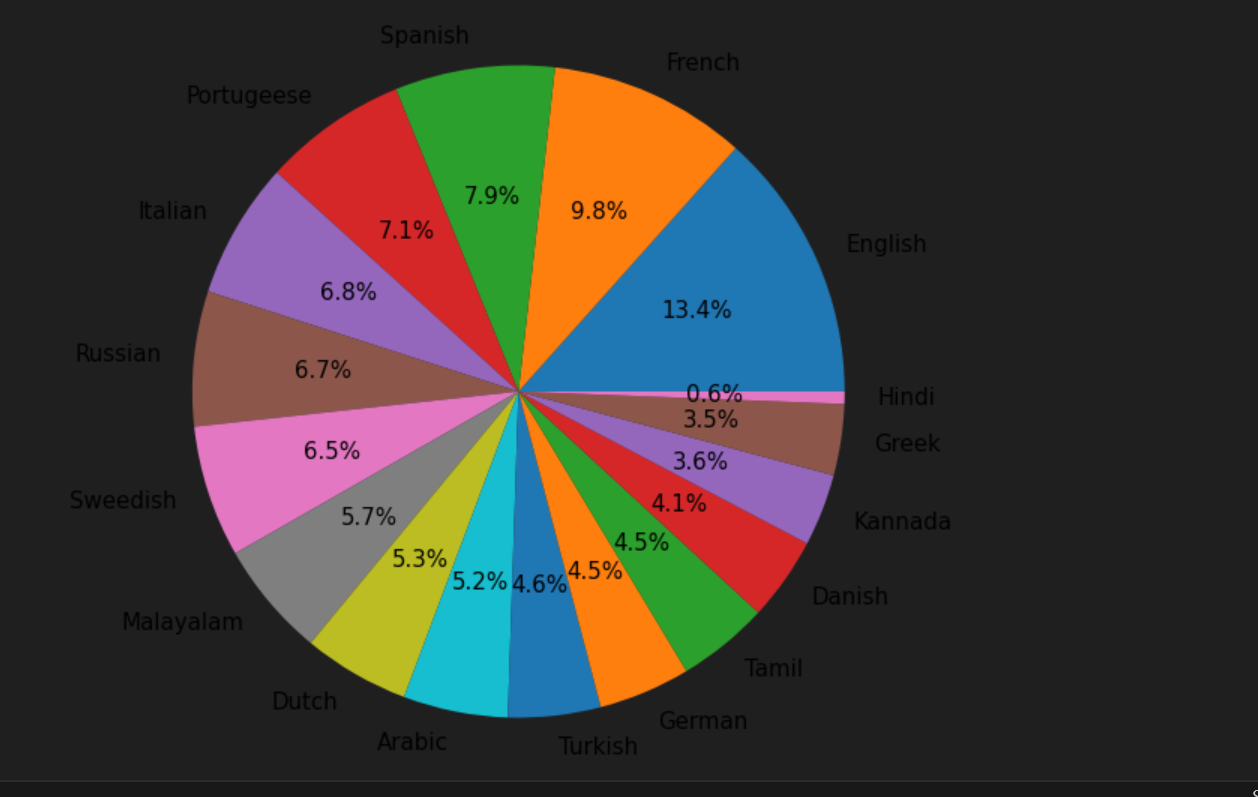
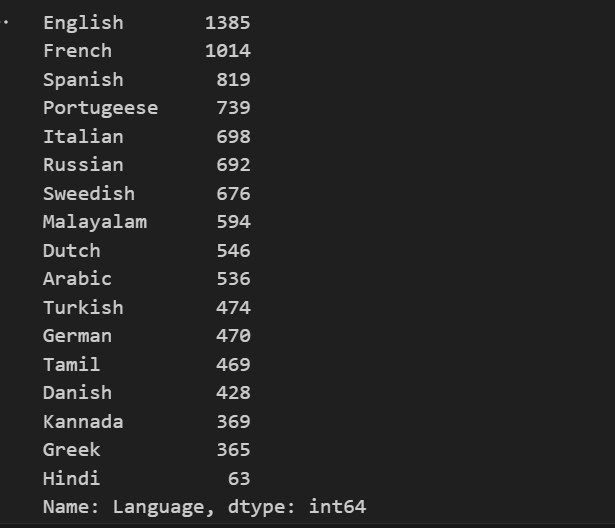
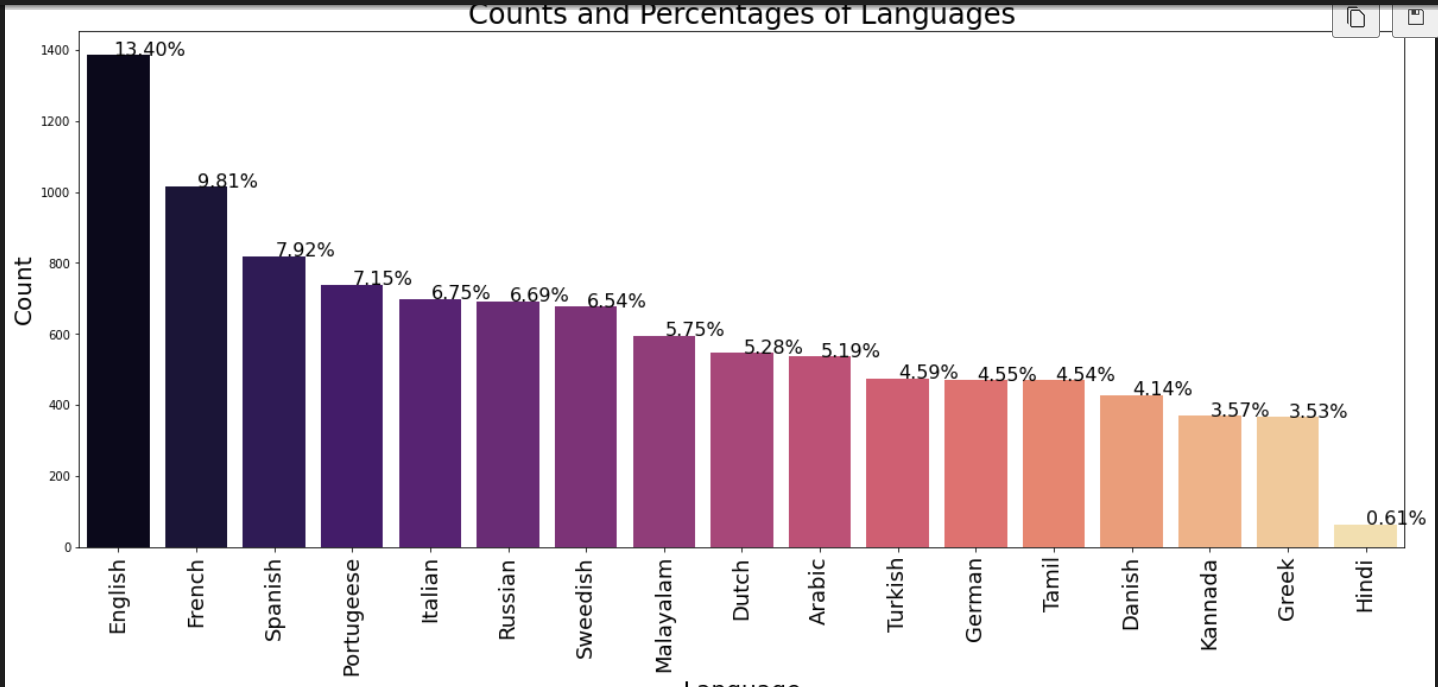
Share this content:






Share this content:


Post Comment